
Why AI Networks Fail (Even With Enough Bandwidth)
Networking Field Day 39 challenged my assumptions about AI infrastructure. The real problems? Traffic imbalance, not capacity. ROCE's sensitivity to packet loss. Why validated designs matter more than specs. Here's what finally clicked for me about why AI networks fail—even with enough bandwidth.

I've been spending a lot of time lately separating signal from noise in AI infrastructure conversations. Especially around networking. And especially around Cisco's networking story.
Networking Field Day 39 showed up at exactly the right moment.
Not because it was a Cisco event—it wasn't. Multiple companies presented. But the Cisco sessions, and more importantly the questions from practitioners in the room, helped several things finally click for me.
If you keep reading, you'll see why 'AI networking' isn't just a backend fabric problem, why bandwidth often isn't the real bottleneck, how Cisco approaches congestion differently, and why operations matter as much as raw performance.
This is me learning out loud. If it gives you an "aha" you can reuse or explain to someone else, it's done its job.
Why NFD39 mattered for this
Networking Field Day events bring together multiple vendors, real engineers, and practitioners who ask the kinds of questions people actually worry about. Tom Hollingsworth, who's been a great friend for years, has built something genuinely valuable with the Field Day format. The interaction often matters as much as the presentation.
I'm a Tech Field Day delegate, but I've never attended one where Cisco presented, so I watched the replay. I focused my time on the Cisco sessions because I'm sharpening my understanding of Cisco's AI networking direction as I build toward Cisco Live Amsterdam.
What really elevated these sessions were the questions. People like Rita Younger, Denise Donohue, Kevin Myers, and others asked exactly the kinds of clarifying, grounding questions that turn abstract architecture into something you can actually reason about. Those exchanges were gold.
I went in thinking I had a solid mental model of AI networking. What surprised me was how incomplete that model actually was. And how much of the real work has very little to do with raw speed.
AI networking is not just a backend fabric
When I hear "AI networking," my brain immediately jumps to GPU-to-GPU communication.
That part absolutely matters. But what Paresh Gupta made clear during Cisco's NFD39 sessions is that an AI cluster is not a single network. It's a collection of networks, each with very different traffic patterns and failure modes.
At a minimum, an AI cluster includes:
- A front-end network for users, applications, and services
- A storage network, often converged with the front end now
- Sometimes a backend storage network, depending on the storage platform
- A dedicated inter-GPU backend network
- A management or out-of-band network
- Plus the surrounding data center fabric that everything connects through
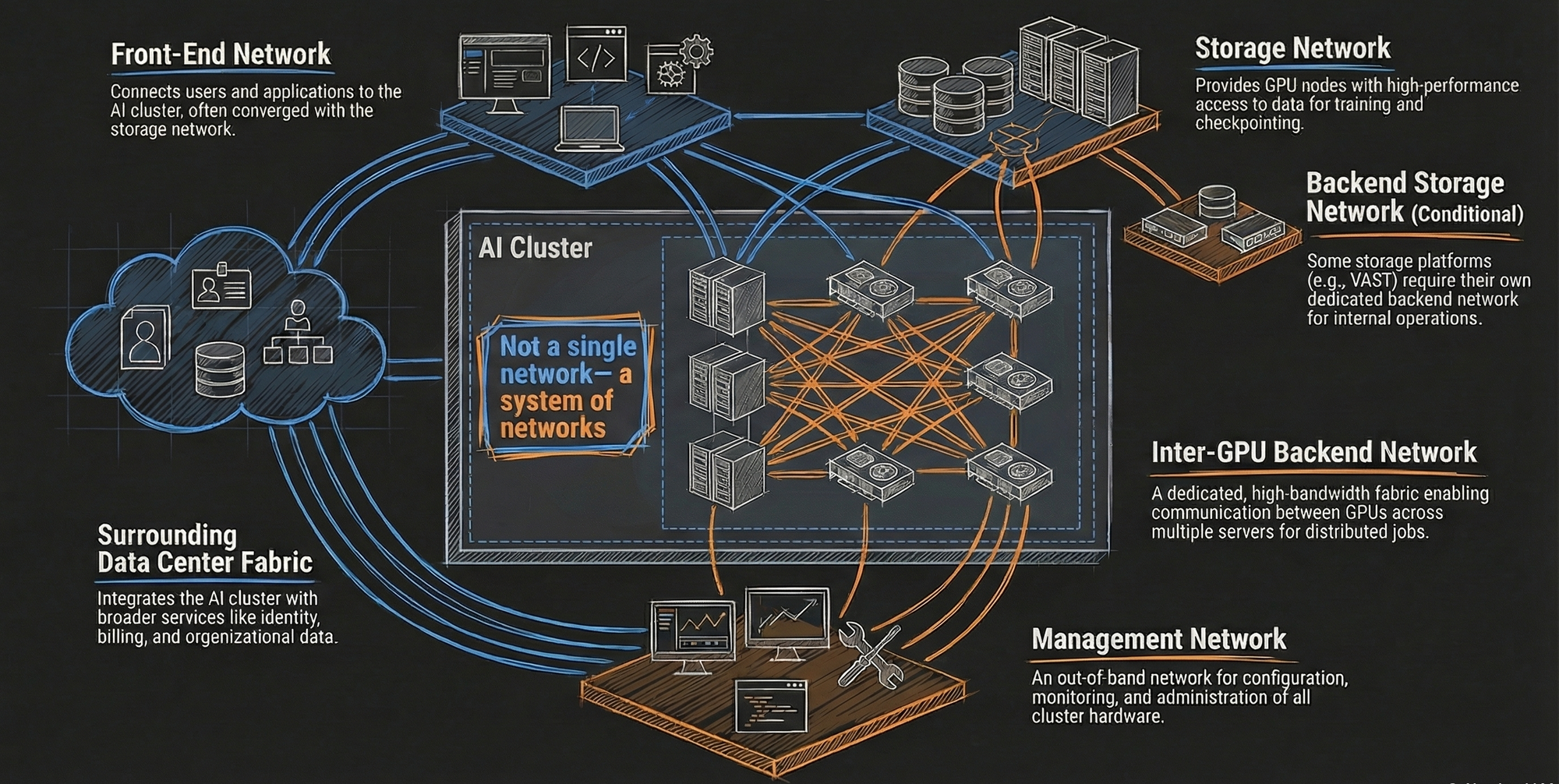
What struck me is how often "AI networking" conversations fixate on the backend fabric and ignore everything else. Cisco is very deliberately not doing that. The design guides and reference architectures treat the AI cluster as a system, not a single problem to optimize in isolation.
When you start thinking about it this way, everything else makes more sense.
Bandwidth is not the real enemy
I walked into these sessions assuming most AI networking problems come down to not having enough bandwidth.
Paresh challenged that assumption quickly.
Modern GPU servers can generate massive amounts of traffic at line rate in real deployments. Eight GPUs per server, each with high-speed NICs, can push 6.4 terabits per second when active. And when GPUs communicate, they don't ramp gently. They go.
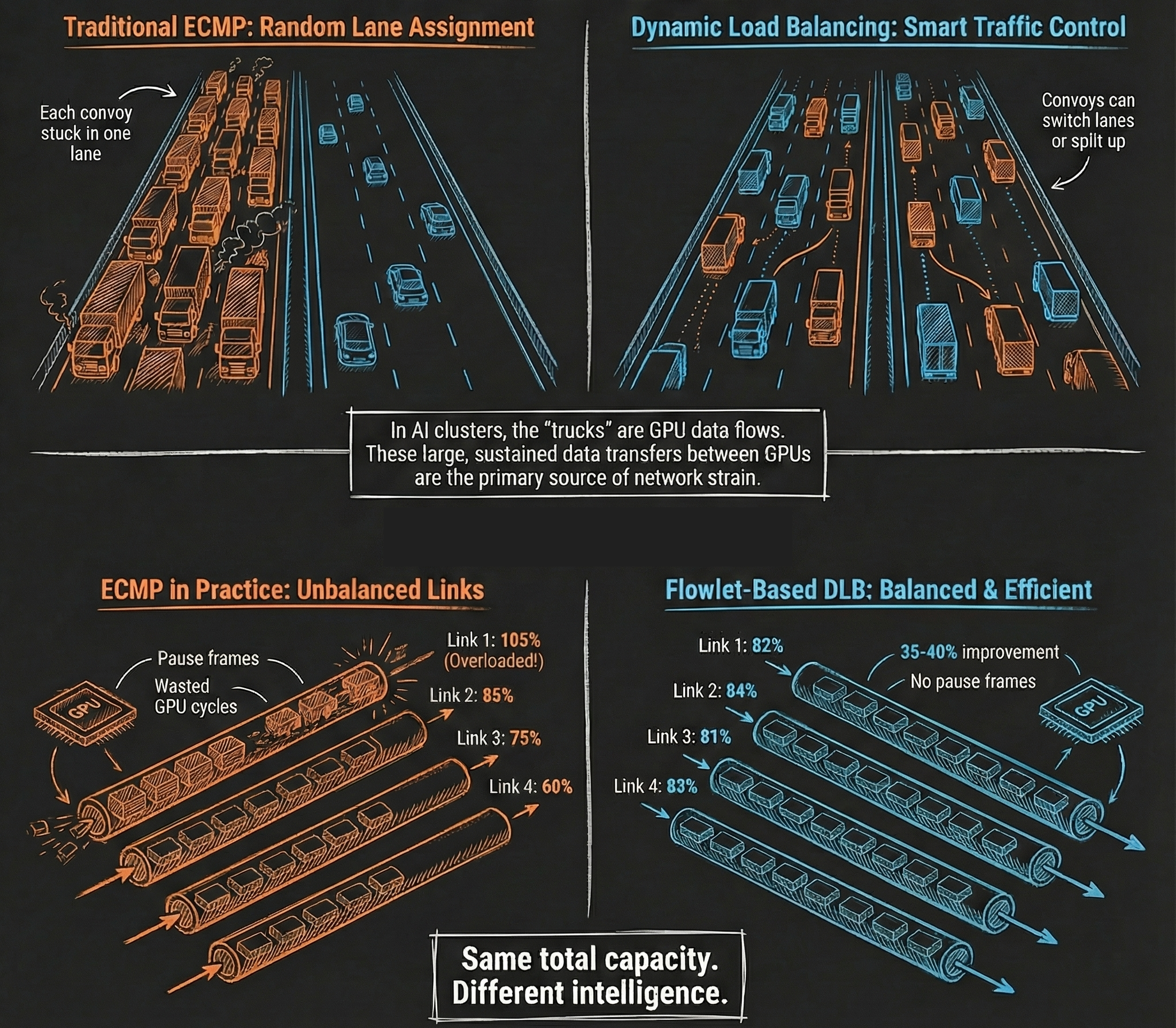
What actually causes trouble is imbalance, not total capacity.
Traditional ECMP load balancing hashes flows randomly. In normal enterprise environments, that's usually fine. In tightly coupled AI workloads, it can be disastrous.
You end up with one link running hot while another sits underutilized. Congestion shows up even though there's plenty of total bandwidth available. That congestion triggers pause frames, packet reordering, and retransmissions.
For collective GPU operations, that's brutal. One delayed or dropped packet can stall an entire job and waste extremely expensive GPU time.
This was a genuine "oh… that explains a lot" moment for me.
Even perfectly sized networks can fail badly if traffic isn't evenly distributed.
ROCE changes the rules completely
Most AI backend networks today use RDMA over Converged Ethernet (ROCE).
That detail matters because ROCE is UDP-based. There's no TCP congestion control safety net. Packet loss doesn't quietly recover in the background. It can stall entire collective operations.
Layer that on top of AI traffic patterns like checkpointing—where all GPUs may write to storage at the same time—and you get massive incast events that traditional network designs were never built to handle.
Paresh emphasized that these environments are extremely sensitive to both packet loss and delay. Microseconds matter. Old assumptions stop working.
Cisco's message here wasn't "this is hard." It was "this is different." Once you understand that, the rest of their approach starts making sense.
Congestion control is now a system problem
Cisco isn't treating congestion control as a single feature or a single box problem.
What Paresh described is a coordinated system, spanning the switch, the NIC, and the operating model.
At the switch level, Cisco's Nexus 9000 Series switches with Silicon One ASICs have moved beyond basic ECMP with dynamic load balancing techniques:
- Flowlet-based load balancing that detects natural gaps in traffic
- Steering new flowlets onto the least congested path
- Per-packet load balancing when finer control is needed
But the more important insight was that the switch doesn't work alone.
Cisco showed a jointly validated reference architecture with NVIDIA, where Cisco Nexus 9000 switches perform per-packet dynamic load balancing while NVIDIA SuperNICs use adaptive routing and direct data placement. The behavior is auto-negotiated between the switch and the NIC.
This wasn't theoretical. They showed benchmark data from a 64-GPU cluster where this approach delivered a 35 to 40 percent improvement in application-level bus bandwidth and virtually eliminated pause frames compared to ECMP.
That's not a spec sheet claim. That's measured behavior.
What stood out to me is that Cisco is leaning into coordination rather than pretending the network can solve everything by itself. Very Cisco, in the best sense.
Why Silicon One matters here
Silicon One's P4-programmable architecture is what makes these dynamic load balancing capabilities possible. Cisco can deliver new transport behaviors without waiting on multi-year hardware redesign cycles. That matters when AI networking techniques are evolving quickly and starting to be standardized through efforts like the **[Ultra Ethernet Consortium](https://www.ultraethernet.org/)**, where Cisco is a steering member. The takeaway for me wasn't "custom silicon is magic"—it was that Cisco is productizing these ideas now, in shipping Nexus platforms, and aligning them with where the industry is going next.
Where this becomes real for enterprises
Arun Annavarapu's session explained how all of this backend sophistication only matters if people can actually deploy and operate it reliably.
Cisco's answer here is prescriptive, validated design combined with tooling that assumes humans will make mistakes. This is delivered through two primary platforms: Nexus Dashboard for on-premises unified management, and Nexus HyperFabric AI as a SaaS-based option where Cisco manages the management software.
A few things stood out: Rail-Optimized Design to keep GPU traffic single hop, performance that depends on perfect physical cabling, automated cabling validation where ports only go green when cabled exactly as designed, customers reporting up to 90 percent reduction in deployment time, and integration with job schedulers to detect inefficient workload placement.
Both platforms can feed data into higher-level aggregation layers like AI Canvas and Splunk for cross-product correlation and advanced analytics.
This is classic Cisco value. Not flashy. But deeply practical.
Cisco has always been good at turning hard engineering problems into repeatable operational outcomes. Seeing that applied directly to AI infrastructure is what convinced me this is more than a slideware story.
One step back
Stepping back for a moment, this helped me understand Cisco's AI networking approach much more clearly.
Cisco isn't trying to out-hyperscale hyperscalers. They're taking techniques hyperscalers already rely on—like flowlet-based dynamic load balancing and coordinated switch-NIC behavior—and turning them into validated, operable systems that enterprises can actually deploy, support, and scale.
The Silicon One ASIC gives them the programmability to keep pace with evolving standards. The Nexus Dashboard and Nexus HyperFabric AI platforms give operators the simplified management layer they need. The jointly validated reference architectures with NVIDIA, AMD, Intel Gaudi, and major storage vendors give customers confidence that the whole system works together.
Feels consistent with Cisco's history. Feels intentional.
Why I'm sharing this
I'm not an engineer. But I've been in this space, mostly from the Cisco side, for a long time. Long enough to recognize when there's real depth behind the announcements.
Writing this out helps me test my own understanding. Sharing it gives others a chance to challenge it, refine it, or reuse it when they need to explain these concepts to someone else.
I'll keep learning as I build toward Cisco Live EMEA in Amsterdam. NFD39 gave me a much clearer foundation than I had before, thanks not just to the presentations, but to the questions and discussions that surfaced during them.
If you want to watch the sessions directly, they're worth your time:
Cisco Presents at Networking Field Day 39
As always, feedback is welcome. That's the whole point of learning out loud.